Learning to Throw on a Franka Panda
ProjectIn this project the aim was to teach the Franka Panda arm to throw using a training environment set up in PyBullet and Gymnasium. Once the environment was set up the robotic arm would be trained to throw objects roughly 1 meter away from the base of the robot. The objective was to train the arm to throw the object to reach the target either directly or by bouncing and see how well it would translate to throwing in the real-world. This is project is inspired by TossingBot.
Video Demo
Environment Setup
The ‘throw’ task and ‘throw’ environment were set up as below:
- The environment had the franka panda arm set up at the origin
- The environment would spawn a square object (green in color) in the gripper of the robot, ready to be thrown
- A goal (shown as translucent green) location world spawn 1 meter in front of the arm, with a 15cm offset in the positive and negative direction of the x and y world axis

Policy Training
Action Space
The policy had either 4 actions or 8 actions it could take depending on the control option:
- in ‘ee’ control mode it drives the end effector position and the gripper width
- in ‘joint’ control mode it drives the 7 joints of the franka arm and the gripper width
Observation Space
The observations given to the policy were:
- end effector position
- end effector orientation as a quaternion
- end effector velocity
- end effector gripper width
- object position
- object orientation as euler angles
- object velocity
- object angular velocity
- goal location
Policy
The policy chosen was Soft Actor-Critic. 3 models of SAC were trained on different joint control types and a deep deterministic policy gradient (DDPG) was trained for comparison.
Here is a comparison of their rewards during training for 320,000 iterations.
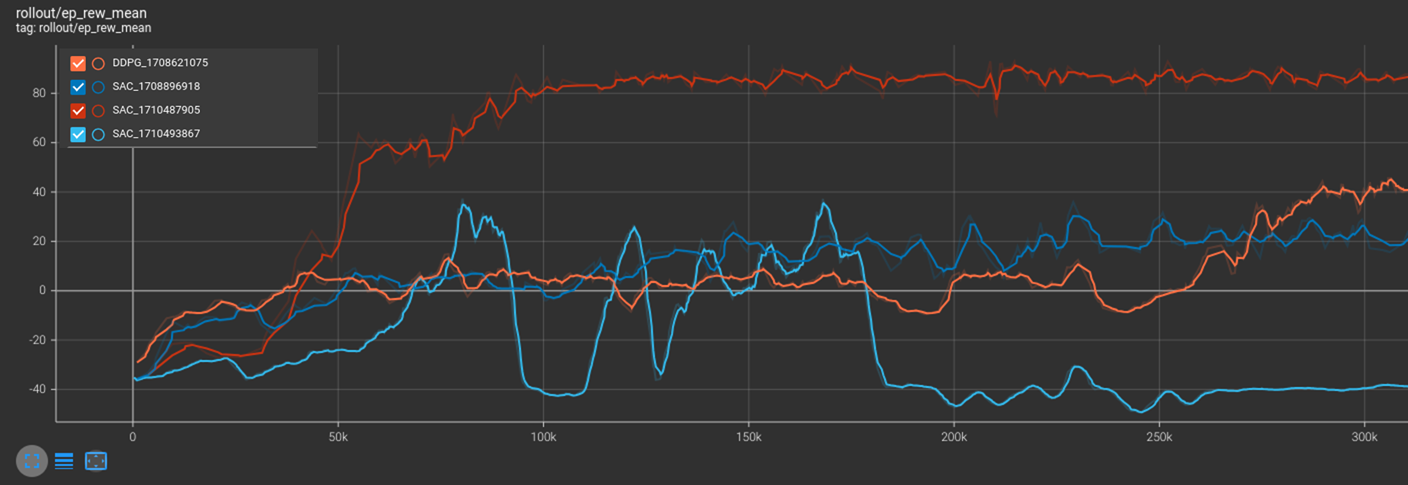
And here is a comparison of their success rate during training for 320,000 iterations.
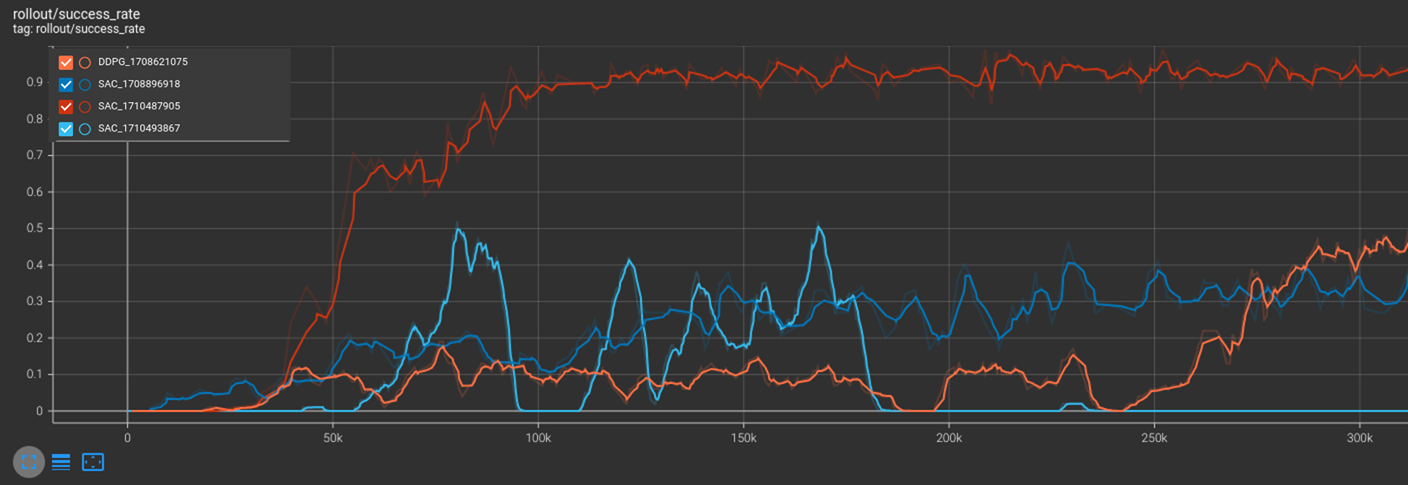
The orange DDPG, red SAC and dark blue SAC(1708896918) policies were using end effector control while the light blue SAC(1710493867) policy was using joint control. The red SAC policy performed the best compared to the other SAC and DDPG of the same control type as the weight of the object was approximately halved from 75g to 30g.
Sim-to-Real

Translating the policy actions from simualtion to the real Franka Arm was only partially successful. This is because the dynamics simulated on PyBullet are not realistic and cannot directly correlate to joint movements on the arm. This was a great inital test however, and can be expanded upon by using different simulators like Mujoco or IssacGym to see how well the sim-to-real transfer works on them. It would also be beneficial to train directly on the Franka with a closed loop system using computer vision to train the robot in the real environment.